

An architecture pattern for highly scalable systems

What is “Streaming Microservices Architecture”?
“Streaming Microservices Architecture” is the architectural pattern in which a system is built of multiple microservices, and those communicate via an event-streaming platform.
Services subscribe to the events that are required for their logic, and publish results.
Similar concepts are referred to as “Event Driven Architecture” or “Pub/Sub Architecture”. The term “Streaming” emphasizes the real-time nature of events processing - events are processed as streams.
The architectural pattern is aimed for systems that are required to process a high volume of inputs, ongoing, with low latency.
Architecture Goals
In order to set the scene and define what we are aiming to achieve, let’s define the key goals of our architecture:
- Scalability: We want the system to scale easily, and be able to handle growing amounts of work.
- Robustness: We want the system to be tolerant to failures.
- High Performance: We want the system to perform its work at low latency and high throughput.
- Extensibility: We want it to be easy to add new functions to the system.
- Low Cost: We want the system to perform its work efficiently, requiring minimal resources.
Implementation
Stateless Services

A stateless service is a service where the processing of an event does not depend on previous events. Example : A service that calculates the square root of a number.
Stateless services are easy to handle:
- Availability and Scaling: Processing of each event is independent of other events, so work is arbitrarily distributed between the instances. When an instance goes down, the work is smoothly distributed between other instances. Same when spinning up new instances for scaling.
- Memory management: The service does not remember data between events, so memory usage is fairly stable and expected.
- Persistent storage: Not required.
- Data consistency: Each event is independent so transactions are straight forward.
- Performance: Usually the amount of work is similar for all events, so performance is stable and expected.
Stateful Services

A stateful service is one that has memory – a state that gets updated according to the received events. Example: A service that calculates hourly average over a stream of events.
Stateful services are more challenging to design. Designing them correctly is in the heart of Streaming Microservices Architecture implementation.
The challenges include:
- Availability and Scaling: Processing of an event depends on previous events, so data should be partitioned by a key in order to guarantee that events that must be processed together arrive at the same instance. When an instance goes down, the work is distributed between other instances. When this happens, the instances that are taking ownership of new partitions need to restore the state. Similar process happens when spinning up new instances for scaling. Since work distribution is by a defined key, and not arbitrary, attention should be given to how balanced the distribution of work is.
- Memory management: Can become tricky, since the size of the state may depend on multiple factors, and it may grow or shrink depending on the events.
- Persistent storage: Prefer to avoid persistent storage, but if really needed - use local persistent storage (See “About Local Storage” section).
- Data consistency: Careful attention should be given to transactions - avoiding cases where an event is processed twice, or not processed at all.
- Performance: May vary depending on state size and specific events. Service startup may be a special scenario, since it may require restoring of the state. Testing different scenarios will provide a view of how the service performs and whether optimizations are required. The scenarios may include: Stable ongoing work, restart of a service instance and starting the service after a period of inactivity.
About Local Storage
As mentioned in the previous section, a stateful service requires storage for its state. The storage can be RAM (preferred) or local persistent storage, but not remote storage. Why?
When processing events, you will need direct access to pieces of the state. Consider, for example, a service calculating hourly average over a stream of events, for one million different time-series. When handling an event, you need to update the state of the time-series to which the event belongs. So the latency of direct access is critical.
Generally speaking, direct access to RAM is much faster than direct access to local persistent storage (SSD), which is much faster than direct access to remote storage:
RAM << local SSD << remote storage.

Roughly speaking, RAM direct access is on the scale of nanoseconds, local SSD is on the scale of microseconds and remote storage is on the scale of milliseconds.
There can be two reasons for using local persistent storage (in addition to RAM):
- The state is too big to economically fit into RAM.
- It is important for the state to be persisted, for fast recovery after restart of the service.
When local persistent storage is used, it should be used together with in-memory caching, to minimize the frequency of having to access the persistent storage.
Comparing to other service communication methods
API calls

Using APIs (e.g. REST) is a common way for microservices to communicate. I’m claiming that inter-service communication via APIs results in a system that is more complicated and prone to failures. Why?
- Coupling: APIs create high coupling, because services know each other, while Pub/Sub promote low coupling - services do not know other services.
- Robustness: With APIs, if one service is temporarily unavailable, dependent services are unavailable, which with Pub/Sub availability of a service does not depend on other services.
- Throttling: With APIs, services must be able to throttle, and service consumers must be ready to be throttled, while with Pub/Sub throttling is not needed.
APIs are synchronous, while Pub/Sub is asynchronous, so what if there is a need for synchronous communication between services? Then re-evaluate the separation to services, maybe the system will be simpler with the required functionality in a single service.
Message Queue

Pub/Sub and Message Queue are both asynchronous, both consist of a platform to handle the delivery of data between services.
A key difference between the two is that with “Message Queue” a message is consumed by a single consumer, while with “Pub/Sub” a message can be consumed by multiple consumers. “Pub/Sub” provides a higher level of decoupling: The sender does not know the receiver.
In “Pub/Sub”, there are no “messages”, there are “events” – facts that are made visible to other services.
Central DB
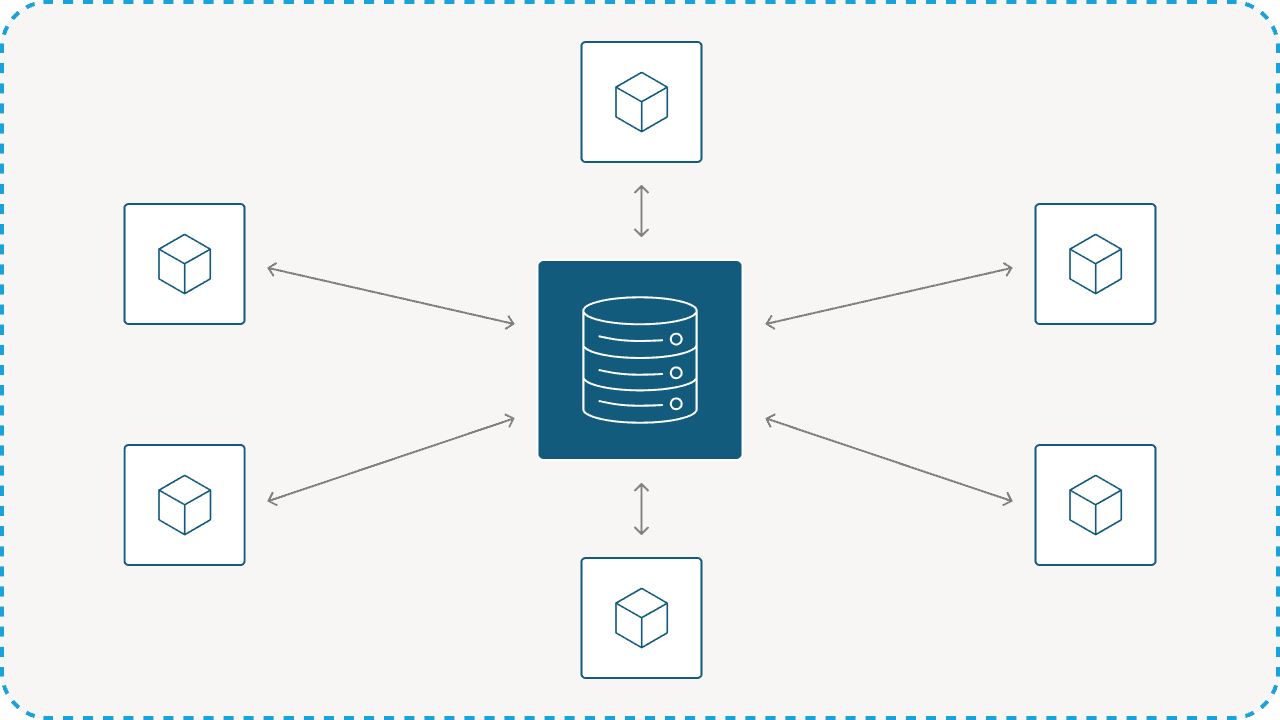
We have discussed the advantages of local storage over remote storage for service state. But sometimes, it feels like sharing data in a central DB will be easier. Maybe the performance requirements are not that strict, maybe different services need access to the same data. Tempted to use central DB? Be strong and avoid it. Why?
- Scalability: With central DB the DB may become a bottleneck, while with Local State, scalability of each service depends on the service itself
- Performance: With central DB services are performing high latency queries on a remote DB which limit their throughput, while with Local State the access is magnitudes faster
- Coupling: With central DB there is high and implicit coupling between services accessing the DB, while with Local State changes are explicitly bounded to subscribed services
- Locks: With central DB, a design that is not careful enough may lead to locking between services trying to access shared data, while with Local State and Pub/Sub there is no shared data accessed by multiple services, so no locks
- Extensibility: With central DB making schema changes for one service may impact others, while with Local State functionality can be extended by adding new services and new topics
- Cost: With central DB, in order to overcome performance drawback, high resources are required for the DB, while Local State allow high performance with low cost
So is the usage of databases strictly forbidden? No… Usage of a central database for service state or as a channel for communication between services is discouraged, but there are other cases where various types of databases are useful. An example for such a case is a “Reporting Database” or “Analytical Database” where data relevant for reporting / visualization / analytics / machine learning, etc. is stored in a way that is optimized for those purposes. Note that in this case, the database is at the end of the processing flow, not a communication channel.
Conclusions
“Streaming Microservices Architecture” is a great architecture pattern for systems that are required to process a high volume of inputs, ongoing, with low latency.
It allows building systems that are highly scalable, robust, efficient, extensible, and cheap to operate.
Using Pub/Sub approach for communication supports low coupling between services.
Services can be stateless or stateful. For stateful services, using local state is a key principle for achieving low latency processing.
Streaming Microservices in Teridion
We have a system with dozens of different microservices and hundreds of service instances running in production. The key architecture pattern is “Streaming Microservices Architecture”. We use Kafka as a streaming platform. The services are written in Scala, some use plain Kafka consumer/producer and some utilize Kafka Streams.
Choosing this architecture pattern has proven to be a great decision. It fully supports our architecture goals: Scalability, Robustness, High Performance, Extensibility, Low Cost.
The system was not “Streaming Microservices” from day one. Shifting to this architecture was done as a growth-supporting transformation, from a more naive, early days implementation. Over time, the pattern became a natural way of thinking for the engineering team.
We still have parts of the system that are reminders of the “old way” (always need to prioritize and make trade-offs…), but when coming to design a new feature, Streaming Microservices Architecture marks the direction.


